tensorflow 搭建简单的卷积神经网络,输入二维数组完成分类 |
您所在的位置:网站首页 › python 二维数组输入 › tensorflow 搭建简单的卷积神经网络,输入二维数组完成分类 |
tensorflow 搭建简单的卷积神经网络,输入二维数组完成分类
|
目录 一、数据处理 二、搭建cnn模型 三、训练并测试模型 一、数据处理导入数据 #导入数据 X=pd.read_csv('data.csv',header=None) X=np.array(test_data) y=pd.read_csv('label.csv',header=None) y=np.array(test_label) print(X.shape) print(y.shape)数据说明:本例中X .shape为(22000, 5) ,y.shape为(22000, 2) 归一化(这里使用L2范数归一化)
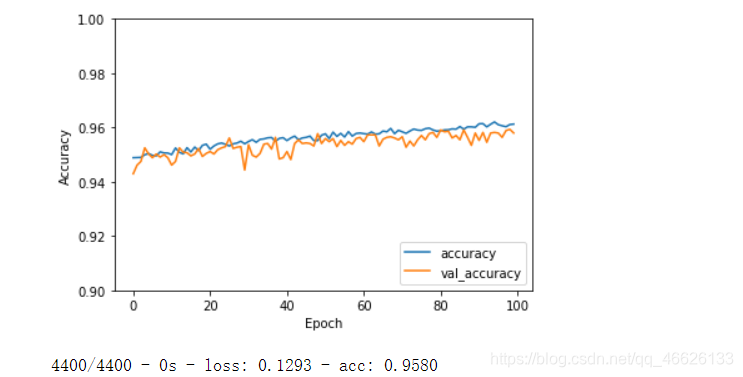
归一化后的数据x[0]如下所示 [0.4666068526196366 0.45379696823113014 0.44562044628101977 0.43935177945260173 0.4298125038441395]扩展输入变量维数 由于cnn网络的输入为四维,所以将本例中的二维数组扩展1为四维 X=X.reshape(22000,5,1,1)将整型的类别标签转为onehot编码 y= np_utils.to_categorical(y)划分测试集 测试集占比百分之20 X_train, X_test, y_train, y_test = train_test_split(X, y,test_size = 0.2) print(X_train.shape) print(X_test.shape) print(y_train.shape) print(y_test.shape) 结果: (17600, 5, 1, 1) (4400, 5, 1, 1) (17600, 2) (4400, 2) 二、搭建cnn模型 引入库 import os import numpy as np import pandas as pd import tensorflow as tf from tensorflow.keras import datasets, layers, models import matplotlib.pyplot as plt cnn模型 model = models.Sequential() model.add(layers.Conv2D(32, (1, 1), activation='relu', input_shape=(5, 1, 1)))#卷积层 model.add(layers.MaxPooling2D((1, 1)))#池化层 model.add(layers.Conv2D(64, (1, 1), activation='relu')) model.add(layers.MaxPooling2D((1, 1))) model.add(layers.Conv2D(64, (1, 1), activation='relu')) model.add(layers.Flatten()) model.add(layers.Dense(64, activation='relu'))#全连接层 model.add(layers.Dense(2, activation='softmax')) print(model.summary())#输出模型模型输出结果 Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_6 (Conv2D) (None, 5, 1, 32) 64 _________________________________________________________________ max_pooling2d_4 (MaxPooling2 (None, 5, 1, 32) 0 _________________________________________________________________ conv2d_7 (Conv2D) (None, 5, 1, 64) 2112 _________________________________________________________________ max_pooling2d_5 (MaxPooling2 (None, 5, 1, 64) 0 _________________________________________________________________ conv2d_8 (Conv2D) (None, 5, 1, 64) 4160 _________________________________________________________________ flatten_3 (Flatten) (None, 320) 0 _________________________________________________________________ dense_8 (Dense) (None, 64) 20544 _________________________________________________________________ dense_9 (Dense) (None, 2) 130 ================================================================= Total params: 27,010 Trainable params: 27,010 Non-trainable params: 0 _________________________________________________________________ None 相关函数参数详解(暂时可不必细看,需要时再查看)1.输入层 参数详解 layers.Input( shape=None, //输入的形状,tuple类型。不含batch_size; batch_size=None,//输入的形状,tuple类型。不含batch_size;声明输入的batch_size大小,一般会 //在预测时候用,训练时不需要声明,会在fit时声明,即dataset类型数据声明了 //batch_size name=None, //给layers起个名字,在整个网络中不能出现重名。如果name=None,则系统会自动为 //该层创建名字。 dtype=None, //数据类型,在大多数时候,我们需要的数据类型为tf.float32,因为在精度满足的 //情况下,float32运算更快。 sparse=False, tensor=None, ragged=False, **kwargs, )2.flatten 返回一个一维数组。 flatten只能适用于numpy对象,即array或者mat,普通的list列表不适用! 用在数组 a = [[1,3],[2,4],[3,5]] a = array(a) a.flatten() 输出:array([1, 3, 2, 4, 3, 5])用在矩阵 a.flatten().A:a是个矩阵,降维后还是个矩阵,矩阵.A(等效于矩阵.getA())变成了数组 具体例子见https://www.pythonf.cn/read/149830。 3.Dense 全连接层 4.Dropout 为了防止或减轻过拟合而使用的函数,它一般用在全连接层 Dropout就是在不同的训练过程中随机扔掉一部分神经元。也就是让某个神经元的激活值以一定的概率p,让其停止工作,这次训练过程中不更新权值,也不参加神经网络的计算。但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了 tf.nn.dropout( x, //输入 keep_prob, //float类型,每个元素被保留下来的概率,设置神经元被选中的概率,在初始化时 //keep_prob是一个占位符, keep_prob = tf.placeholder(tf.float32) 。 //tensorflow在run时设置keep_prob具体的值,例如keep_prob: 0.5 noise_shape,// 1D 整数张量, 表示将与输入相乘的二进制 dropout 掩层的形状。 例如,如果 //你的输入尺寸为 (batch_size, timesteps, features),然后 你希望 dropout //掩层在所有时间步都是一样的, 你可以使用 noise_shape=(batch_size, 1, //features)。 seed=None, //整型变量,随机数种子 name=None //指定该操作的名字 )5.models.Sequential() 该方法是一个容器,描述了神经网络的网络结构,可用model.add()语句在容器中添加各层 6.layers.Conv2D() 搭建卷积层,activation为激活函数 7.layers.MaxPooling() 池化层 三、训练并测试模型 导入包 from tensorflow.python.keras.callbacks import EarlyStopping, CSVLogger, ModelCheckpoint from tensorflow.python.keras.optimizers import *保存模型 my_callbacks = [EarlyStopping(patience=4), ModelCheckpoint('D:\\hhhh.h5', save_best_only=True,save_weight_only = False)]配置训练方法,告知训练时用的优化器、损失函数和准确率评测标准 model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])训练并测试 history = model.fit(X_train,y_train, epochs=100,validation_data = (X_test,y_test), workers=4, use_multiprocessing=True, batch_size = 256, callbacks=my_callbacks)结果: Epoch 98/100 17600/17600 [==============================] - 2s 99us/sample - loss: 0.1167 - acc: 0.9603 - val_loss: 0.1314 - val_acc: 0.9589 Epoch 99/100 17600/17600 [==============================] - 2s 99us/sample - loss: 0.1193 - acc: 0.9611 - val_loss: 0.1275 - val_acc: 0.9593 Epoch 100/100 17600/17600 [==============================] - 2s 99us/sample - loss: 0.1168 - acc: 0.9613 - val_loss: 0.1293 - val_acc: 0.9580 plt.plot(history.history['acc'], label='accuracy') plt.plot(history.history['val_acc'], label = 'val_accuracy') plt.xlabel('Epoch') plt.ylabel('Accuracy') plt.ylim([0.9, 1])#设置坐标上下限 plt.legend(loc='lower right') plt.show() test_loss, test_acc = model.evaluate(X_test,y_test, verbose=2)结果如下
函数式模型接口 - Keras中文文档 1.callbacks 模型断点续训:保存当前模型的所有权重提早结束:当模型的损失不再下降的时候就终止训练,当然,会保存最优的模型。动态调整训练时的参数,比如优化的学习速度。(1)EarlyStopping 当监测值不再改善时,该回调函数将中止训练 keras.callbacks.EarlyStopping( monitor='val_loss', #需要监视的量,即评价指标 patience=0, #当early stop被激活(如发现loss相比上一个epoch训练没有下降),则经过 patience个epoch后停止训练。 verbose=0, #信息展示模式 mode='auto' #‘auto’,‘min’,‘max’之一,在min模式下,如果检测值停止下降则中止训练。在 max模式下,当检测值不再上升则停止训练。 )(2)ModelCheckpoint 存储最优的模型 keras.callbacks.ModelCheckpoint( filepath, #存储的位置和模型名称,以.h5为后缀 monitor='val_loss', #检测的指标 verbose=0, #信息展示模式,0或1 save_best_only=False, #当设置为True时,将只保存在验证集上性能最好的模型 save_weights_only=False, #若设置为True,则只保存模型权重,否则将保存整个模型(包括模型结构,配 置信息等) mode='auto', #‘auto’,‘min’,‘max’之一,在save_best_only=True时决定性能最佳模型 的评判准则,例如,当监测值为val_acc时,模式应为max,当检测值为 val_loss时,模式应为min。在auto模式下,评价准则由被监测值的名字自动 推断。 period=1 #CheckPoint之间的间隔的epoch数 )(3)model.compile 在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准 详见官网 优化器optimizers - Keras中文文档 目标函数objectives - Keras中文文档 model.compile(optimizer = 优化器, loss = 损失函数, metrics = ["准确率”] #列表,包含评估模型在训练和测试时的性能的指标,典型用法是 metrics=['accuracy']如果要在多输出模型中为不同的输出指 定不同的指标,可像该参数传递一个字典,例如metrics= {'ouput_a': 'accuracy'} 比如如下参数: "accuracy" : y_ 和 y 都是数值,如y_ = [1] y = [1] (y_为真实值,y为预测值) “sparse_accuracy":y_和y都是以独热码 和概率分布表 示,如y_ = [0, 1, 0], y = [0.256, 0.695, 0.048] "sparse_categorical_accuracy" :y_是以数值形式给出,y 是以独热码给出,如y_ = [1], y = [0.256 0.695, 0.048](4)model.fit 执行训练过程 fit( self x, #输入数据。如果模型只有一个输入,那么x的类型是numpy array,如果模型有 多个输入,那么x的类型应当为list,list的元素是对应于各个输入的numpy array。如果模型的每个输入都有名字,则可以传入一个字典,将输入名与其 输入数据对应起来。 y, #标签,numpy array。如果模型有多个输出,可以传入一个numpy array的list。 如果模型的输出拥有名字,则可以传入一个字典,将输出名与其标签对应起来。 batch_size=None, #整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本会 被计算一次梯度下降,使目标函数优化一步。 epochs=1, #整数,训练终止时的epoch值,训练将在达到该epoch值时停止,当没有设置 initial_epoch时,它就是训练的总轮数, 否则训练的总轮数为epochs - inital_epoch verbose=1, #日志显示,0为不在标准输出流输出日志信息,1为输出进度条记录,2为每个 epoch输出一行记录 callbacks=None, #回调函数 validation_split=0.0, #0~1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集将不参 与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注 意,validation_split的划分在shuffle之后,因此如果你的数据本身是有序 的,需要先手工打乱再指定validation_split,否则可能会出现验证集样本不 均匀。 validation_data=None, #形式为(X,y)或(X,y,sample_weights)的tuple,是指定的验证集。此 参数将覆盖validation_spilt shuffle=True, #布尔值,表示是否在训练过程中每个epoch前随机打乱输入样本的顺序 class_weight=None, #字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失函 数(只能用于训练)。该参数在处理非平衡的训练数据(某些类的训练样本数 很少)时,可以使得损失函数对样本数不足的数据更加关注。 sample_weight=None, #权值的numpy array,用于在训练时调整损失函数(仅用于训练)。可以传递一 个1D的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据 时,传递一个的形式为(samples,sequence_length)的矩阵来为每个时间步 上的样本赋不同的权。这种情况下请确定在编译模型时添加了 sample_weight_mode='temporal'。 initial_epoch=0, #从该参数指定的epoch开始训练,在继续之前的训练时有用。 steps_per_epoch=None, #一个epoch包含的步数(每一步是一个batch的数据送入),当使用如 TensorFlow数据Tensor之类的输入张量进行训练时,默认的None代表自动分 割,即数据集样本数/batch样本数。 validation_steps=None #仅当steps_per_epoch被指定时有用,在验证集上的step总数 )fit函数返回一个History的对象,其History.history属性记录了损失函数和其他指标的数值随epoch变化的情况,如果有验证集的话,也包含了验证集的这些指标变化情况 |
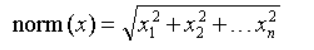
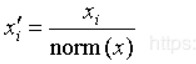
【本文地址】
今日新闻 |
推荐新闻 |